 yansanmo
collectionneur amateur de données
yansanmo
collectionneur amateur de données
Analyse
Livrable par le DBA d'un diagramme de contexte (UML cas d'utilisation), d'un diagramme Entité/Relation (E/R ou diagramme de structure statique ou diagrammes de classes)
Une entité, représenté par un rectangle, sera convertit en table ou en classe.
Un attribut, représenté par un oval, sera convertit en champ.
Cas d'utilisation
Diagramme de contexte avec l'indentifications des acteurs et des actions. On peut exploser ou décomposer les actions en sous actions (ou sous-cas d'utilisation).
On inclut généralement dans la description textuelle du cas d'utilisation ces champs:
- nom;
- description courte;
- type;
- description (avec le quand ou les évènements déclencheurs et le comment);
- règles du domaine d'application (les contraintes d'intégrité);
- exigence de performance; (par exemple le temps de réponse)
- exigence de sécurité;
Diagramme de structure statique
Diagrammes de classes - entité/relation
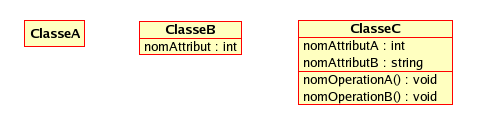
Une classe ou entité représenté par un rectangle possède un nom (première case en haut), des attributs (champs) et des méthodes (opérations). Le nom de la classe est obligatoire tandis que les deux dernières cases ne le sont pas.
Les attributs peuvent avoir des valeurs par défaut et des types, la syntaxe est: NomAttribut : Type = ValeurDefaut. Le type et la valeur ne sont pas obligatoires.
??? {propriété : {modifiable}/fixe | {changeable}/frozen | insertionSeulement (addOnly)
On peut spécifier la portée des attributs ainsi que souligner l'attribut s'il est statique.
Les attributs dérivés (ou calculés) sont spécifier à l'aide d'une barre oblique / devant le nom de l'attribut.
Opération: nom (type de paramètre) : type de retour. L'opération peut être réelle, abstraite ou statique. Habituellement, les modifieurs (setter) commencent par set, les lecteurs (getter) commencent par get.
On peut spécifier des contraintes sur des champs en les spécifiant entre accolade et placé avant le champ. Par exemple, pour spécifier que le champ 'champ1' est unique on note:
{UNIQUE: champ1}
champ1
La contrainte UNIQUE peut se faire sur plusieurs champs, en les séparant par des virgules.
Les classes virtuelle (qu'on ne peut créer seules) sont spécifier en placant le nom de classe en italique.
Pour spécifier des contraintes sur plusieurs classes, on utilise une Note et on relie les classes à la note avec une ligne pointillée. On peut aussi placer une note sur une ou plusieurs associations.
La multiplicité s'indique de plusieurs manières: 1 (uniquement un), 0..1 (0 à 1), 0..N (0 à N), * (0 à l'infini).
Un objet, une instance d'une classe, possède une identité (identifiant), un état (attributs et valeurs) et des comportements (méthodes). L'Object Identifier (OID) est l'identifiant de l'objet.
Stéréotype
- «entité»
- Représente une entité
- «datatype»
- Spécifie qu'une classe est un type de données (pour les autres classes)
Les liens sont des associations entre deux objets (ou instances de classe).
Relationnel: début le 25 janvier (simon: départ)
Cas d'utilisation à rédiger: simon=pair, yan=impair.
Ajout des contraintes sur le E/R: yan
1- Doit-on insérer les valeurs par défaut dans le schéma relationnel?
2- À quel niveau de détails doit on faire les cas d'utilisation? (niveau du champ, ou juste nommer les actions, séries d'étapes), cas alternatifs?
Rôle et cardinalité obligatoire dans le premier schéma.
Choix:
1- Adresse champ string dans Client.
1. pour simplifier les tables (ne pas créer une table uniquement pour cette fonction)
2. limiter le nombres de caractères pour le champ adresse
3. permettre un choix plus varier lorsque le client entre son adresse sans modifier la base de données
2- Selon le chargé de lab pour le formalisme du modèle relationel dans rational rose
1. Utiliser <nomEntité>s (au pluriel) pour le nom des tables
2. Ne pas utiliser le stéréotype table
3. Ne pas mettre les valeurs par défaut
4. On peut utiliser STRING au lieu de varchar
5. {clé primaire: nom champ}
champ : type
3- Numéro de commande est en format String car on pourrait vouloir afficher un numéro comme 000001, 000002, etc...
Fait: Yan: use case...
Yan: Ajouter "Date de disponibilité"
Yan: décrire les descriptions des entités et des attributs
Yan: perfectionner le diagramme entité-relation
Simon: contrainte
Simon: perfectionner le Diagramme relationnel
Hyperliens...